
[이코노믹데일리] 카카오(대표 정신아)가 텍스트를 넘어 음성과 이미지를 동시에 이해하고, 한국어의 미묘한 뉘앙스와 문화적 맥락까지 파악하는 고도화된 멀티모달(Multi-modal) 인공지능(AI) 모델을 선보였다.
카카오는 12일 테크블로그를 통해 통합 멀티모달 언어모델 ‘카나나-오(Kanana-o)’와 멀티모달 임베딩 모델 ‘카나나-브이-임베딩(Kanana-v-embedding)’의 개발 성과를 공개했다. 이번 발표는 지난 5월 카나나 모델의 초기 성능을 공개한 이후 실제 사람과 대화하듯 자연스러운 상호작용 능력과 한국어 특화 기능을 대폭 강화한 결과물이다.
‘카나나-오’는 텍스트와 음성 및 이미지를 실시간으로 동시에 처리하는 통합 모델이다. 기존 멀티모달 모델들이 텍스트 입력에는 강하지만 음성 대화 시 반응이 단순해지거나 부자연스러웠던 한계를 극복하는 데 주력했다. 카카오는 자체 구축한 고품질 데이터셋을 활용해 카나나-오의 지시 이행 능력을 고도화했다. 이를 통해 사용자의 복잡한 요구사항이나 숨은 의도를 파악하고 단순 질의응답을 넘어 요약, 번역, 감정 해석, 오류 수정 등 다양한 과업을 수행할 수 있게 됐다.
특히 주목할 점은 향상된 감정 표현 능력이다. 직접 선호 최적화(DPO) 기술을 적용해 기쁨, 슬픔, 분노 등 상황에 맞는 생생한 감정을 목소리에 실을 수 있다. 미세한 억양이나 호흡 변화까지 학습해 마치 사람과 대화하는 듯한 느낌을 준다. 팟캐스트 형태의 대화 데이터를 학습시켜 대화가 끊김 없이 자연스럽게 이어지는 ‘멀티턴(Multi-turn)’ 대화 능력도 갖췄다.
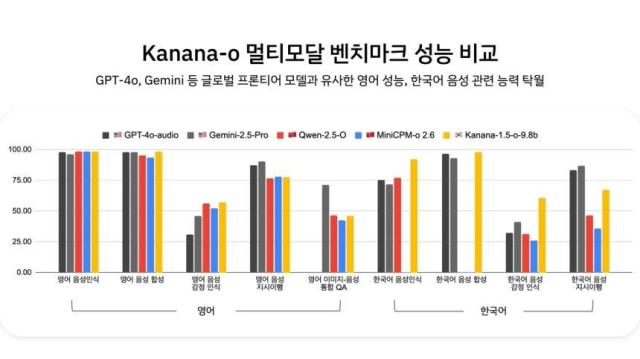
벤치마크 테스트 결과, 카나나-오는 영어 음성 성능에서 오픈AI의 최신 모델인 ‘GPT-4o’와 유사한 수준을 기록했다. 특히 한국어 음성 인식과 합성 및 감정 인식 능력에서는 월등히 높은 점수를 기록하며 한국형 AI로서의 경쟁력을 입증했다.
함께 공개된 ‘카나나-브이-임베딩’은 이미지 검색 특화 모델이다. 텍스트와 이미지를 동시에 이해해 사용자가 원하는 이미지를 정확히 찾아준다. ‘경복궁’이나 ‘붕어빵’ 같은 한국 고유 명사는 물론 ‘하멜튼 치즈’처럼 오타가 섞인 검색어에서도 문맥을 파악해 정확한 결과를 제시한다. ‘한복 입고 찍은 단체 사진’과 같은 복합적인 조건도 정밀하게 구분해낸다. 현재 이 기술은 카카오 내부 광고 시스템에 적용되어 유사도 분석 및 심사에 활용되고 있다.
카카오는 현재 모바일 기기에서도 원활하게 구동되는 온디바이스(On-device)용 경량화 모델 연구를 진행 중이다. 아울러 전문가 혼합(MoE) 구조를 적용해 성능과 효율을 극대화한 차세대 모델 ‘카나나-2’ 개발에도 속도를 내고 있다.
김병학 카카오 카나나 성과리더는 “카나나는 단순 정보 전달을 넘어 사용자 감정을 이해하고 한국적 맥락에서 자연스럽게 소통하는 AI를 지향한다”며 “실제 서비스 환경에 이를 적용해 일상 속에서 체감할 수 있는 AI 경험을 만들어가겠다”고 말했다.










































댓글 더보기